Redshiftへのデータ流し込み(Batch)
Batchを作ることになったので、そちらを書いていきます。warningを解消する際にすでに公開していたバッチですが、コードを改善したのでまた載せていきます。
サンプルコードは参考までにしてください。
前提
検討・方針
AWS DATAPIPEを利用することも検討したけれど、テーブル毎に定義を増やさなければいけないので、管理しづらいと思いこちらは辞めた。APPにタスクを作成して、バッチ処理することで対応する。ただし、migrationに伴うテーブル定義の変更をRedShift側に伝播できる仕組みはないので、こちらは手動でsqlを回すことになる。(データコピーで利用するテーブルカラムを限定して、設計の時間を稼ぐこともできるがそれも今回はやらない)
処理の流れは、
- dumpファイルの作成し1GBを超える場合は分割(updated_atで期間は絞る)
- S3へアップロード
- コピー用テーブルを作成
- コピー用テーブルにデータコピー
- コピー用テーブルとターゲットテーブルでマージして、UPSERTを実行
- コピー用テーブルを削除
です。
RDBに処理するファイルとステータスを登録・更新し、タスク完了時には、Slackへ通知。(サンプルコードには載せていません)
dumpファイルの作成し1GBを超える場合は分割(updated_atで期間は絞る)
Redshift のCOPY SQLコマンドは、データを複数ファイルに分割することが推奨されています。
注記 データを複数のファイルに分割し、並列処理の長所を最大限に活用することをお勧めします。
分割するファイル数は、ノード数 x スライス数の倍数になります。ds2.xlargeのノードタイプを利用しているので4ファイルに分割します。
S3へのアップロード
分割したファイル全てを所定のフォルダにアップロードします。今回model.idのフォルダを作成して、その直下にファイルをアップロードします。
コピー用テーブルを作成
テーブルの属性値は、実際に使われているテーブルを元に作成します。そうすることでコピー用テーブルの管理コストをなくします。
コピー用テーブルにデータコピー
COPYコマンドによりコピー用テーブルにデータをコピーします。
コピー用テーブルとターゲットテーブルでマージして、UPSERTを実行
コピー用テーブルの削除
課題(解決済み含む)
ノードタイプの変更に際して、ノードのストレージ使用量をみているが、テンポラリテーブルを利用することで一時的に使用量が増えることになる。 => タスクが動いた際に使用量の閾値を超えた場合にもアラートが出るので、このアラートが出たらタイプを変更する想定です。 アラートに起因しているかは、その時に調査する。
DBのマイグレーションの追随 => これが課題。Rails migrationを利用しているが、この変更にRedshift側のテーブルを追随させる必要がある。今回は, READMEに追加して、注意喚起しているが、migrationコマンドにフックする形でスクリプトを走らせることと、定義をmigrationから解析して反映させるツールを作ることを検討する。
調査と実装で重く、放置しても運用面で負荷が大きい。
参考
文字列の連結(`#+`, `#{}`)のベンチマーク
質問されてどうなのか知らなかったので、ベンチマークを取ってみた。
- ruby 2.2.10 - macOS - 3.3 GHz Intel Core i7
コード(sample利用)
require 'benchmark'
Benchmark.bm 10 do |r|
r.report "#r+" do
result = ''
1000000.times do
chr = [*'a'..'z'].sample
result += chr
end
end
r.report "#r{}" do
result = ''
1000000.times do
chr = [*'a'..'z'].sample
result = "#{result}#{chr}"
end
end
end
sampleの計算量を考慮していないので、sampleメソッドを利用しないコードでもベンチマークをとります。
コード(sample利用)
require 'benchmark'
Benchmark.bm 10 do |r|
r.report "#r+" do
result = ''
100000.times do
chr = "a"
result += chr
end
end
r.report "#r{}" do
result = ''
100000.times do
chr = "a"
result = "#{result}#{chr}"
end
end
# おまけで測定(結果2回のみ)
r.report "#r<<" do
result = ''
100000.times do
chr = "a"
result << chr
end
end
end
結果
# 単位は秒
# sample利用コード
user system total real
#r+ 0.930000 0.250000 1.180000 ( 1.190557)
#r{} 1.130000 0.560000 1.690000 ( 1.749810)
user system total real
#r+ 0.920000 0.210000 1.130000 ( 1.127887)
#r{} 1.010000 0.360000 1.370000 ( 1.395523)
user system total real
#r+ 0.970000 0.330000 1.300000 ( 1.324458)
#r{} 1.010000 0.370000 1.380000 ( 1.388045)
user system total real
#r+ 0.970000 0.270000 1.240000 ( 1.246748)
#r{} 0.990000 0.320000 1.310000 ( 1.319941)
user system total real
#r+ 0.870000 0.170000 1.040000 ( 1.039002)
#r{} 1.180000 0.690000 1.870000 ( 1.920898)
user system total real
#r+ 1.030000 0.390000 1.420000 ( 1.459395)
#r{} 0.970000 0.300000 1.270000 ( 1.284337)
user system total real
#r+ 0.890000 0.220000 1.110000 ( 1.117645)
#r{} 1.020000 0.320000 1.340000 ( 1.341777)
user system total real
#r+ 1.020000 0.430000 1.450000 ( 1.470244)
#r{} 1.160000 0.550000 1.710000 ( 1.927555)
# sample利用なしコード
user system total real
#r+ 0.810000 0.780000 1.590000 ( 1.595337)
#r{} 0.890000 0.870000 1.760000 ( 1.769899)
user system total real
#r+ 0.790000 0.740000 1.530000 ( 1.542483)
#r{} 0.950000 1.030000 1.980000 ( 2.017400)
user system total real
#r+ 0.800000 0.780000 1.580000 ( 1.594527)
#r{} 0.910000 1.020000 1.930000 ( 2.001948)
user system total real
#r+ 0.850000 0.840000 1.690000 ( 1.733741)
#r{} 0.920000 0.950000 1.870000 ( 1.893551)
user system total real
#r+ 0.800000 0.780000 1.580000 ( 1.585265)
#r{} 0.910000 0.890000 1.800000 ( 1.809907)
user system total real
#r+ 0.780000 0.750000 1.530000 ( 1.560372)
#r{} 0.910000 0.930000 1.840000 ( 1.838491)
user system total real
#r+ 0.790000 0.750000 1.540000 ( 1.552678)
#r{} 0.920000 0.950000 1.870000 ( 1.874736)
user system total real
#r+ 0.770000 0.740000 1.510000 ( 1.545361)
#r{} 0.920000 1.030000 1.950000 ( 2.017822)
# おまけ
user system total real
#r+ 0.810000 0.800000 1.610000 ( 1.654600)
#r{} 0.970000 1.090000 2.060000 ( 2.197110)
#r<< 0.020000 0.010000 0.030000 ( 0.019684)
user system total real
#r+ 0.810000 0.780000 1.590000 ( 1.606184)
#r{} 0.950000 1.020000 1.970000 ( 1.994647)
#r<< 0.030000 0.000000 0.030000 ( 0.035348)
ベンチマーク結果
#+ 0.870000 - 1.030000
#{} 0.990000 - 1.180000
#+ 0.770000 - 0.850000
#{} 0.890000 - 0.920000
#<< 0.020000 - 0.030000
結論しては、ruby 2.2.10では、#r+と#{}では、#+が早いと言えました。
以上です。
shellコマンドのエスケープ[Ruby]
Rubyからシェルコマンドを実行する(Kernel.#system ..etc)
調べていたので、書いていきます。
前提
- Ruby 2.2.10
外部コマンドの呼び出し
実装で利用したは、#system, #`を利用していて、コマンドを実行して返却値、ステータスは無視するケースと返却値を利用するケースで分けて使っています。
Kernel.#system
引数を外部コマンドとして実行して、成功した時に真を返します。 子プロセスが終了ステータス 0 で終了すると成功とみなし true を返します。 それ以外の終了ステータスの場合は false を返します。 コマンドを実行できなかった場合は nil を返します。 終了ステータスは変数 $? で参照できます。 コマンドを実行することができなかった場合、多くのシェルはステータス 127 を返します。(したがって $? の数値は、0x7f00)、シェルを介 さない場合は Ruby の子プロセスがステータス 127 で終了します。 コマンドが実行できなかったのか、コマンドが失敗したのかは、普通 $? を参照することで判別可能です。
Kernel.#`
command を外部コマンドとして実行し、その標準出力を文字列として 返します。このメソッドは
commandの形式で呼ばれます。exec
引数で指定されたコマンドを実行します。 プロセスの実行コードはそのコマンド(あるいは shell)になるので、 起動に成功した場合、このメソッドからは戻りません。
Kernel.#spawn
引数を外部コマンドとして実行しますが、生成した 子プロセスの終了を待ち合わせません。生成した子プロセスのプロセスIDを返します。
サンプル
コードの切り抜きを載せます。このままだと動かないです。
参考
AWSのメモリ使用量のモニタリング
EC2のメモリ使用量を継続的に監視するために、cloudwatchに転送するAWS公式で出しているスクリプトを利用した。new_rericが入ったんだけれども、みれる状況じゃなかった。(諸事情)
前提
方針
EC2のメモリ・スワップ使用量は、EC2のモニタリングでは確認できないので、perlのスクリプトをEC2上で実行・5分感覚でスケジュールする。 かつ、障害の問題になったプロセス・タスクは特定できたので、その実行頻度を毎分から毎日1回に変更した。
これにより原因が解消されているかを監視して、事象が発生した場合に検知できる仕組みとして、CPU使用率が75%以上で5分継続した場合にアラートメールを配信するようにSNSに連絡先のメールアドレスを設定した。
EC2への設定
Amazon Linux AMI Amazon Linux AMI バージョン 2014.03 以降を実行している場合は、追加の Perl モジュールをインストールする必要があります。
上記に当てはまるので、この手順に従います。
$ ssh ec2-user@example.com $ sudo yum install perl-Switch perl-DateTime perl-Sys-Syslog perl-LWP-Protocol-https -y
モニタリングスクリプトをダウンロードする
$ curl https://aws-cloudwatch.s3.amazonaws.com/downloads/CloudWatchMonitoringScripts-1.2.2.zip -O
モニタリングスクリプトのインストール
unzip CloudWatchMonitoringScripts-1.2.2.zip rm CloudWatchMonitoringScripts-1.2.2.zip cd aws-scripts-mon
IAMをユーザに
cloudwatch:PutMetricData # このロールはなし ec2:DescribeTags # このロールはなし
スクリプトのフォルダ内の認証情報を入力する。
ファイルをリネームする。
$ cp awscreds.template awscreds.conf
IAMユーザのaccess keyとsecret keyを入力する。
# awscreds.conf AWSAccessKeyId=my-access-key-id AWSSecretKey=my-secret-access-key
テストラン(Cloud Watchにデータは送らない)
./mon-put-instance-data.pl --mem-util --verify --verbose
CloudWatchにレポートするメトリクスをのcronスケジュールを設定する
crontab -e */5 * * * * /home/user_name/aws-scripts-mon/mon-put-instance-data.pl --mem-used-incl-cache-buff --mem-util --disk-space-util --disk-path=/ --from-cron
これでAWS consoleからサービス「CloudWatch」から「メトリクス」を選択する
--disk-space-util --disk-space-used --disk-space-avail
今回は外していますが、ディスクの情報についてもレポートでみたいので、オプションもつけています。

確認できるようになる。
続いて、「アラート」を選択する
CPUUtilization (CPUUtilization)閾値値が75%以上で、5分継続
名前: [ec2 name] CPUUtilization ALERT
説明:CPUUtilization ALERT
>= 75
欠落データの処理方法: 見つかりません
アラートが次の時: 警告
通知の送信先: SNS(トピックに登録し、メールアドレスにメールが配信されるので許可する)
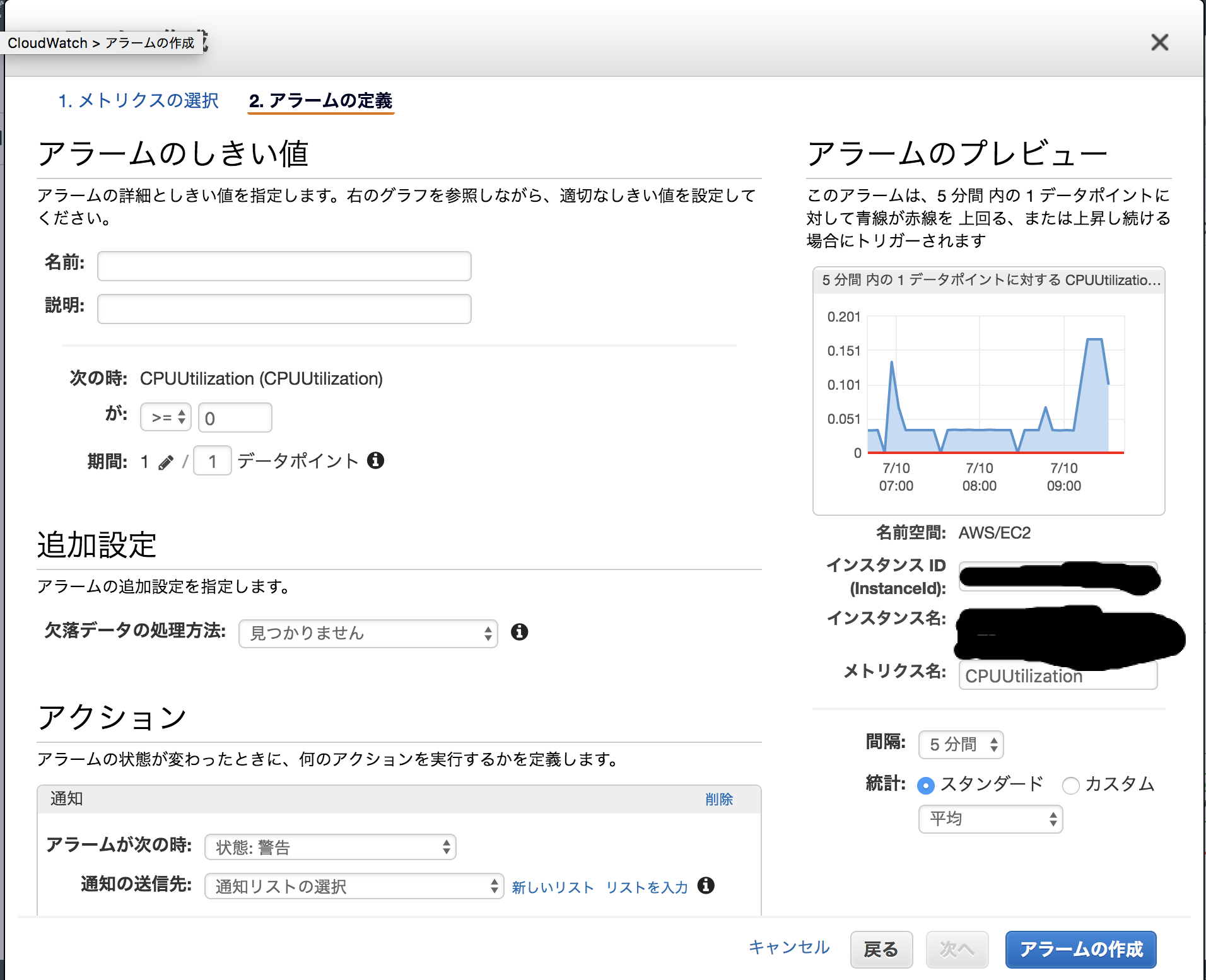
アラートを作成する。
以上。
課題
- ロードアベレージについてもみたい。
- 監視ツールに寄せたい。
参考
Amazon EC2 Linux インスタンスのメモリとディスクのメトリクスのモニタリング - Amazon Elastic Compute Cloud
mysql([Warning] Using a password on the command line interface can be insecure.)
コマンドファイルを作っている際に出てきたので、警告を表示しないようにする。
前提
解決方法
confファイルを利用して、client情報を渡すことにする。
confファイルから読み込む
以上。
参考
MySQL :: MySQL 5.6 リファレンスマニュアル :: 6.1.2.1 パスワードセキュリティーのためのエンドユーザーガイドライン
sidekiq + redisの構築(Rails 4系) 4-1
インフラの準備を分割して書いていきます。
前提環境:
検証環境として、立てていきます。(EC2はのぞく)
EC2
EC2は立てている前提で、サーバにsshで接続して、redis(client)とmonitをインストール
# ssh -i ~/.ssh/[秘密鍵] ec2-user@example.co.jp $ sudo yum install -y monit $ sudo rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm $ sudo yum --enablerepo=remi install redis
ElasticCache(Redis 4)
費用面を抑えたいということで冗長性を犠牲にし、将来的に依存する構成・機能になった際には、タイプを上げること、ノードを増やして1ノードが落ちた際の対応を進めて、冗長性を高める(想定)。
要件が集計用のデータを扱うので、redisの障害により止まったとして、復旧後、再アップロードすることでよしとしてもらう(相談済)
アプリ側の制限として
- redisのメモリ不足を発生させないように、クラスのインスタンスを渡せるのだが、idを渡す。
- キューにエンキューするジョブは、再度ジョブを入力しても同じ結果になるようにする(通知系、データ集計.. etc)
- キューに保存する前に、DBにアクションのレコードを保存する
非同期で扱えるキューが有用なのは判断できているので、信頼性をそのほか(アプリケーション、DB)で担保します。(完全には不可能な場合は、再実行で対応できるように)
Elastic Cache
サービスからElastic Cacheを選択する。

サイドメニューからRedisを選択する。
作成するボタンを選択する

Redisの設定
- 名前: redis_
- 説明:
- エンジンバージョン:4.0.10
- ポート: 6379
- パラメータグループ: default.redis4.0
- ノードのタイプ: t2.cache.t2.micro
- レプリケーション数: 2
- 自動フェイルオーバーを備えたマルチAZ: チェック無し
- サブネット: デフォルト
- 優先アベイラビリティゾーン: 指定なし
セキュリティ
- セキュリティグループ: redis-cache: 6379をインバウンドで許可したセキュリティグループ(EC2に追加)
- 保管時の暗号化: チェック無し
- 送信時の暗号化: チェック無し
クラスターへのデータのインポート シードするRDBファイルのS3の場所:
バックアップ: 自動バックアップの有効か: チェック無し
メンテナンス メンテナンスウィンドウ: 指定無し
SNS通知のトピック: 通知の無効化
作成ボタンを選択する
次にクラスター名をクリックして、プライマリエンドポイントをコピーしてアプリケーションから参照できるようにする。

課題
サイズ変更に伴う指標の確認
スケーリング問題の早期通知の取得 – リシャーディングは計算処理能力を集中的に使用するオペレーションであるため、リシャーディング中は CPU 使用率をマルチコアインスタンスで 80% 未満、シングルコアインスタンスで 50% 未満にすることをお勧めします。Redis 用 ElastiCache メトリックスをモニタリングして、アプリケーションでスケーリングの問題が発生する前にリシャーディングを開始します。追跡すると有用なメトリックスは、CPUUtilization、NetworkBytesIn、NetworkBytesOut、CurrConnections、NewConnections、FreeableMemory、SwapUsage、BytesUsedForCache です。
上記の通知が発生した段階で利用するノードタイプを変更するタイミングの指標にする。
クラスター・レプリケーションへの変更タイミングの時間帯
また、メンテナンスのタイミングについて、今回指定無しにしているが、クラスター・レプリケーションへの変更を延期している場合にメンテナンスのタイミングで変更が行われる。この期間を指定して、変更時のアクセス障害が起きるのを回避もしくは起きづらい時間帯に指定する。(深夜帯にアクセスが起きづらいタイプのサービスでは、深夜帯に指定する) (ダウンタイムが発生する恐れがあり、ユーザのアクセスを防げない場合には、アプリのメンテナンスとして、ユーザに通知する措置が必要になってくる)
参考
Amazon ElastiCache (インメモリキャッシュ管理・操作サービス) | AWS
Redshiftへのデータの流し込みについて
環境の違いでスクリプトを変えたので、そちらを載せます kikeda1104.hatenablog.com
SQLファイル -> sh
# tab区切りでファイル出力: dump.shとする PASSWORD=password mysql -u username -p"$PASSWORD" -h hostname db -e "select * from table_name" > /tmp/table_name.txt
コマンド実行
bash dump.sh
s3へのアップロード
s3へのアップロード aws認証情報を登録 awsのIAMからaccess_key, secret_access_keyを取得、なければ作成する。defaultは登録されているので、プロファイル名は別で定義する。 $ aws configure --profile profile_name AWS Access Key ID [None]: access_key AWS Secret Access Key [None]: secret_access_key Default region name [None]: ap-northeast-1 Default output format [None]: json shファイルを作る syncコマンドを利用してアップロードします。shファイルを作ります。 # upload_to_s3.sh aws s3 sync /tmp/txts s3://bucket_name/txts --profile profile_name --exclude '*' --include '*.txt' .... shファイルを実行 bash upload_to_s3.sh # 結果 move: /tmp/table_name.txt to s3://bucket_name/txts/table_name.txt # 成功 move failed: /tmp/table_name.txt to s3://bucket_name/txts/table_name.txt Could not connect to the endpoint URL: "endpoing" #失敗
tsvファイル出力(MySQL)とaws s3アップロード - kikeda1104's blog
テーブル定義
redshiftにテーブルを作る。 # tables.sql create table tables ( id BIGINT NOT NULL PRIMARY KEY, name VARCHAR(255), created_at TIMESTAMP, updated_at TIMESTAMP ); ソートキーは無視します。 mysql側に定義したテーブルのカラム順番とredshiftのカラムの順番を一致させている。 値を流し込む場合にredshiftの仕様により流し込みが失敗・エラーになるケースがあります。 String length exceeds DDL length Mysqlで扱うVARCHARの仕様のズレによりRedshiftではsizeを変更。 渡された数値を文字数として扱うかバイト数で扱うかの違い postgresql clientからredshiftに接続して、テーブルを作ります。 コマンドを簡易化するためにshファイルを作っておく。 # redshift.sh psql -Uusername poscalc --host=endpoint -p port # redshiftのusernameに対応したpasswordを入力する bash redshift.sh < tables.sql
テーブル定義/データインポート(Amazon Redshift) - kikeda1104's blog
s3からRedShift
#copy_to_redshift.sh \timing copy table_name from 's3://bucket_name/txts/table_name.txt' iam_role 'arn:aws:iam::664020506447:role/RedshiftRoleForClient' region 'ap-northeast-1' blanksasnull emptyasnull delimiter '\t' NULL AS 'NULL' ; ...
参考
Redshiftの環境構築
Redshiftの環境構築について書いていきます。
前提
RedShift
データサイズが増加量を計測して毎月1GB増える
- 将来的にデータサイズが、クラスターのストレージを超える可能性も検討してサイズ変更ができるように設計
- Snapshotを利用したデータサイズの変更により停止せずにスケールを予定する。
構築
サービスから「Amazon Redshift」を選択する。
「クラスターを起動」を選択。

項目を入力する。
- クラスター識別子: my-dw-instance
- データベース名: mydb (省略するとdev)
- データベースポート: 5439
- マスタユーザ名: awsuser




確認画面になりますので、「クラスターの起動」を選択します。
IAM(ロールを作成)
aws cliからCOPYコマンドを実行するために、ロールを登録します。
サービスから「IAM」を選択する。 「ロール」-> 「ロール作成」を選択

「Redshift」 -> 「RedShift -Customizable」を選択して「次のステップ: アクセス権限」
「AmazonRedshiftFullAccess」、「AmazonS3ReadOnlyAccess」を割り当てます。
「次のステップ: 確認」を選択する。

- ロール名: ClientForRedshift
- ロール説明: デフォルト
- 「ロールを作成」を選択します。
概要
- このロールのARNをRedShiftのコマンドで利用する(今回はここまで)

RedshiftにIAMをsyncする。
サービスから「Amazon Redshift」を選択する。
クラスターをチェックボックスをチェックして、「IAMロールの管理」を選択。
追加したロール「ClientForRedshift」を選択して、「変更の適用」を選択。
クラスターステータスが、「使用可能」になれば完了です。
費用感
無料枠の場合は、750時間まで無料になっており、複数ノードの場合はより速く無料期間が無くなります。
ちなみに、(2018/07/04時点では) タイプ別の費用感はこちら。

参考
Basic認証(S3 + CloudFront + Lamdba)
コーポレートサイトを作っていて検証として公開したいが、閲覧の制限をかけたかったので急ぎめでBasic認証をかけました。
前提
環境構築
- Lamdbaで、リュージョンをバージニア北部にする。
画像は、一度lambdaの関数を作成したことがない場合です。「関数」を作成ボタンをクリックする。

名前: CorporateWebsite
- ランタイム: Node js 6.10
- ロール: デフォルト(テンプレートから新しいロールを作成)
- ロール名: lambda_edge_exection
- ポリシーテンプレート: Basic Edge Lamdba アクセス権限
- 関数の作成をクリックする

関数コードにコードを貼り付ける。user, passwordは変更すること。
ヘッダーの「保存」をクリックする。(画像は切れています)

ヘッダーのアクションからバージョン発行をクリックする。
バージョンの説明を書き、発行をクリックする。
ARNをコピー(保存)する。($lastestではなく、発行したバージョンになっていることを確認)(画像は$LATESTです)

CloudFront
- Distributionsを選択して、Distribution Settingsをクリックする。
タブからBehaviorsを選択する。
該当のBehaviorsを選択して、Editボタンをクリックする。

Lambda Function Associations Event Typeは、 viewer Requestを選択して、Lambda Function ARNにコピーしておいたARNを入力する。
Yes, Editをクリックする。
確認
サイトにアクセスして、Basic認証がかかっているか確認する。
かかっていることが確認できたので、完了です。
